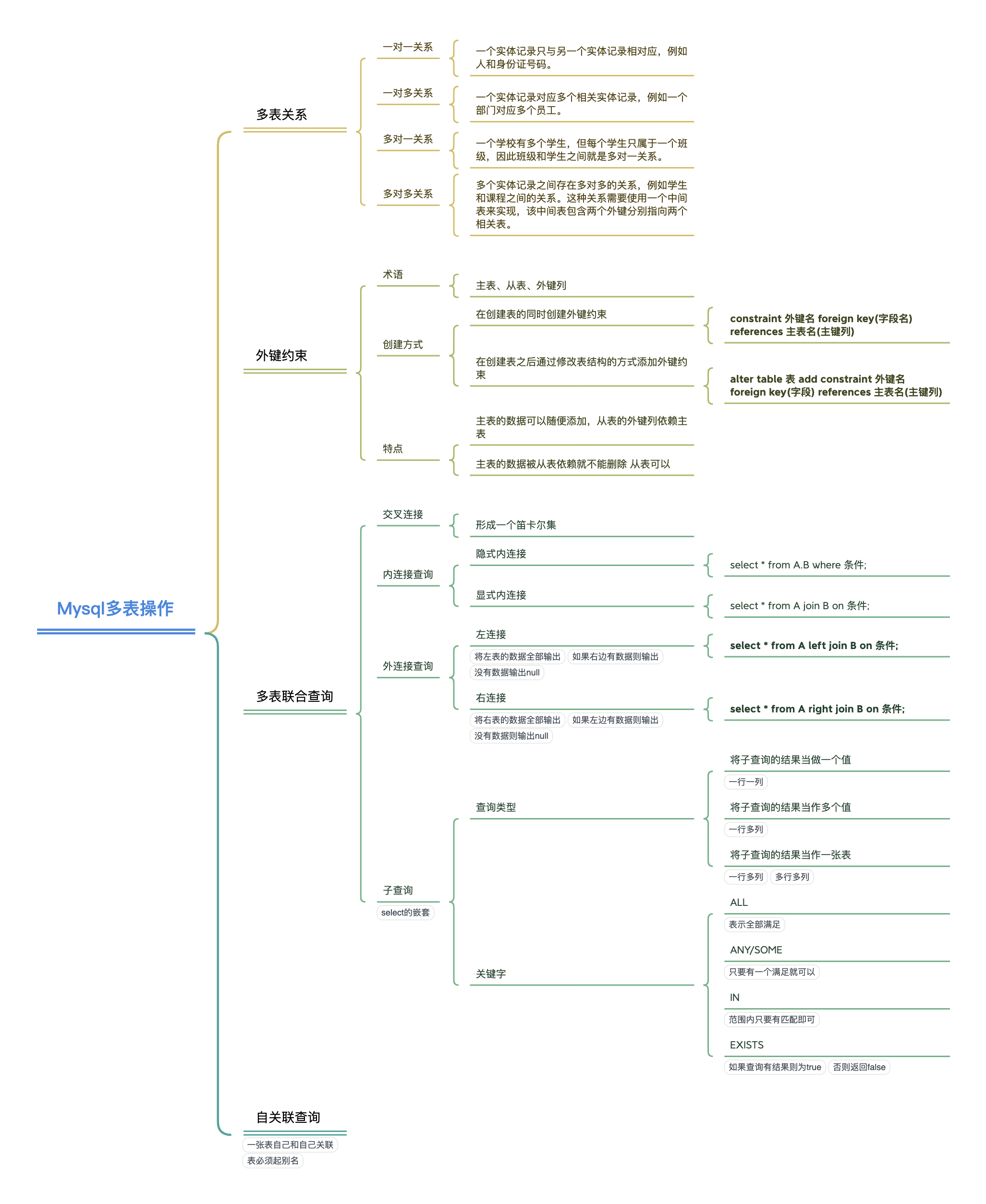
Mysql进阶篇上
外键约束
- 从表列绑定到主表的列,可以保证数据的完整性和一致性。
- 主键不可以有空值 外键允许空值
- 单列主键和联合主键需要与外键一致
- 外键中的数据类型必须和主键的数据类型相同
- 外键允许NULL值,但如果外键列定义为NOT NULL,则不允许NULL值。
- 外键必须引用主表中已经存在的记录
- 主键和唯一约束都可以作为外键的参照对象
- 外键在删除或更新主表记录时会有不同的行为选项,如CASCADE、SET NULL、RESTRICT等
| 属性 | 说明 |
|---|---|
| constraint 外键名 foreign key(字段名) references 主表名(主键列) | 外键约束 |
| alter table 表 add constraint 外键名 foreign key(字段) references 主表名(主键列) | 外键约束 |
-- 创建库
create database blogdx1;
-- 切换库
use blogdx1;
-- 创建部门表 主
create table dept(
deptno varchar(20) primary key, -- 部门号
name varchar(20) -- 部门名字
);
-- 创建员工表 从
create table emp(
eid varchar(20) primary key , -- 员工编号
ename varchar(20), -- 员工名字
age int, -- 员工年龄
dept_id varchar(20), -- 员工所属部门
constraint emp_fk foreign key(dept_id) references dept(deptno)
);
-- 数据插入
-- 1.添加主表数据
insert into dept values('1001','销售部');
insert into dept values('1002','人力部');
insert into dept values('1003','研发部');
insert into dept values('1004','财务部');
insert into dept values('1005','俱乐部');
-- 查看主表内容
select * from dept;
+--------+-----------+
| deptno | name |
+--------+-----------+
| 1001 | 销售部 |
| 1002 | 人力部 |
| 1003 | 研发部 |
| 1004 | 财务部 |
| 1005 | 俱乐部 |
+--------+-----------+
-- 2.添加从表数据
-- 给从表添加数据时 外键列的值不能随便写 必须依赖主表的主键列
insert into emp values('1','乔峰','20','1001');
insert into emp values('2','段誉','21','1001');
insert into emp values('3','虚竹','23','1002');
insert into emp values('4','阿紫','18','1002');
insert into emp values('5','扫地僧','35','1003');
insert into emp values('6','李秋水','33','1004');
insert into emp values('7','鸠摩智','50','1004');
insert into emp values('8','带头大哥','60','1006'); -- 报错
-- 查看从表内容
select * from emp;
+-----+-----------+------+---------+
| eid | ename | age | dept_id |
+-----+-----------+------+---------+
| 1 | 乔峰 | 20 | 1001 |
| 2 | 段誉 | 21 | 1001 |
| 3 | 虚竹 | 23 | 1002 |
| 4 | 阿紫 | 18 | 1002 |
| 5 | 扫地僧 | 35 | 1003 |
| 6 | 李秋水 | 33 | 1004 |
| 7 | 鸠摩智 | 50 | 1004 |
+-----+-----------+------+---------+
delete from dept where deptno = '1001'; -- 不可以删除
delete from dept where deptno = '1005'; -- 可以删除 从表没有依赖
delete from emp; -- 从表可以全部删除
-- 删除外键约束
-- alter table 表名 drop foreign key 外键名
alter table emp drop foreign key emp_kf;
多表查询
- 多表查询就是同时查询两个或者两个以上的表
笛卡尔积
- 笛卡尔积是指两个集合中的所有元素按照一定规则组合在一起形成的新集合
-- 部门编号表
create table dept(
deptno varchar(20) primary key, -- 部门号
name varchar(20) -- 部门名字
);
-- 部门表
create table emp(
eid varchar(20) primary key, -- 员工编号
ename varchar(20), -- 员工名字
age int, -- 员工年龄
dept_id varchar(20) -- 员工所属部门
);
insert into dept values('1001','研发部');
insert into dept values('1002','销售部');
select * from dept;
+--------+-----------+
| deptno | name |
+--------+-----------+
| 1001 | 研发部 |
| 1002 | 销售部 |
+--------+-----------+
insert into emp values('1','乔峰',20,'1001');
insert into emp values('2','段誉',21,'1001');
insert into emp values('3','虚竹',23,'1001');
select * from emp;
+-----+--------+------+---------+
| eid | ename | age | dept_id |
+-----+--------+------+---------+
| 1 | 乔峰 | 20 | 1001 |
| 2 | 段誉 | 21 | 1001 |
| 3 | 虚竹 | 23 | 1001 |
+-----+--------+------+---------+
-- 查询两个表内容 会形成笛卡尔积
select * from dept,emp;
+--------+-----------+-----+--------+------+---------+
| deptno | name | eid | ename | age | dept_id |
+--------+-----------+-----+--------+------+---------+
| 1002 | 销售部 | 1 | 乔峰 | 20 | 1001 |
| 1001 | 研发部 | 1 | 乔峰 | 20 | 1001 |
| 1002 | 销售部 | 2 | 段誉 | 21 | 1001 |
| 1001 | 研发部 | 2 | 段誉 | 21 | 1001 |
| 1002 | 销售部 | 3 | 虚竹 | 23 | 1001 |
| 1001 | 研发部 | 3 | 虚竹 | 23 | 1001 |
+--------+-----------+-----+--------+------+---------+内连接
- 内连接是一种关系型数据库中的数据表连接方式,它返回两个表中满足指定条件的行。只有同时存在于两个表中的行才会被返回,未匹配上的行将被忽略。
- 求多张表的共同部分
- 内连接通常使用 SQL 中的 JOIN 关键字来实现。
| 属性 | 说明 |
|---|---|
| select * from a,b where 条件; | 隐式连接(已过时) |
| select * from 表 join 表 on 条件; | 显式连接 |
-- 部门编号表
create table dept(
deptno varchar(20) primary key, -- 部门号
name varchar(20) -- 部门名字
);
-- 部门表
create table emp(
eid varchar(20) primary key, -- 员工编号
ename varchar(20), -- 员工名字
age int, -- 员工年龄
dept_id varchar(20) -- 员工所属部门
);
insert into dept values('1001','研发部');
insert into dept values('1002','销售部');
insert into dept values('1003','财务部');
insert into dept values('1004','人事部');
insert into emp values('1','乔峰',20,'1001');
insert into emp values('2','段誉',21,'1001');
insert into emp values('3','虚竹',23,'1001');
insert into emp values('4','阿紫',18,'1001');
insert into emp values('5','扫地僧',85,'1002');
insert into emp values('6','李秋水',33,'1002');
insert into emp values('7','鸠摩智',50,'1002');
insert into emp values('8','天山童姥',60,'1003');
insert into emp values('9','莫荣博 ',58,'1003');
insert into emp values('10','丁春秋',71,'1005');
select * from dept;
+--------+-----------+
| deptno | name |
+--------+-----------+
| 1001 | 研发部 |
| 1002 | 销售部 |
| 1003 | 财务部 |
| 1004 | 人事部 |
+--------+-----------+
select * from emp;
+-----+--------------+------+---------+
| eid | ename | age | dept_id |
+-----+--------------+------+---------+
| 1 | 乔峰 | 20 | 1001 |
| 10 | 丁春秋 | 71 | 1005 |
| 2 | 段誉 | 21 | 1001 |
| 3 | 虚竹 | 23 | 1001 |
| 4 | 阿紫 | 18 | 1001 |
| 5 | 扫地僧 | 85 | 1002 |
| 6 | 李秋水 | 33 | 1002 |
| 7 | 鸠摩智 | 50 | 1002 |
| 8 | 天山童姥 | 60 | 1003 |
| 9 | 莫荣博 | 58 | 1003 |
+-----+--------------+------+---------+
-- 查询每个部门的所属员工 隐式连接
select * from dept d,emp e where d.deptno=e.dept_id;
-- 隐式连接
select * from dept d
join emp e
on d.deptno = e.dept_id;
+--------+-----------+-----+--------------+------+---------+
| deptno | name | eid | ename | age | dept_id |
+--------+-----------+-----+--------------+------+---------+
| 1001 | 研发部 | 1 | 乔峰 | 20 | 1001 |
| 1001 | 研发部 | 2 | 段誉 | 21 | 1001 |
| 1001 | 研发部 | 3 | 虚竹 | 23 | 1001 |
| 1001 | 研发部 | 4 | 阿紫 | 18 | 1001 |
| 1002 | 销售部 | 5 | 扫地僧 | 85 | 1002 |
| 1002 | 销售部 | 6 | 李秋水 | 33 | 1002 |
| 1002 | 销售部 | 7 | 鸠摩智 | 50 | 1002 |
| 1003 | 财务部 | 8 | 天山童姥 | 60 | 1003 |
| 1003 | 财务部 | 9 | 莫荣博 | 58 | 1003 |
+--------+-----------+-----+--------------+------+---------+
-- 查询研发部门的所属员工
select * from dept d
join emp e
on d.deptno = e.dept_id where name = '研发部';
+--------+-----------+-----+--------+------+---------+
| deptno | name | eid | ename | age | dept_id |
+--------+-----------+-----+--------+------+---------+
| 1001 | 研发部 | 1 | 乔峰 | 20 | 1001 |
| 1001 | 研发部 | 2 | 段誉 | 21 | 1001 |
| 1001 | 研发部 | 3 | 虚竹 | 23 | 1001 |
| 1001 | 研发部 | 4 | 阿紫 | 18 | 1001 |
+--------+-----------+-----+--------+------+---------+
-- 查询研发部和销售部所属员工
select * from
dept d join emp e
on d.deptno = e.dept_id
where (name = '销售部' or name = '研发部');
select * from dept d join emp e on d.deptno = e.dept_id and name in('研发部','销售部');
+--------+-----------+-----+-----------+------+---------+
| deptno | name | eid | ename | age | dept_id |
+--------+-----------+-----+-----------+------+---------+
| 1001 | 研发部 | 1 | 乔峰 | 20 | 1001 |
| 1001 | 研发部 | 2 | 段誉 | 21 | 1001 |
| 1001 | 研发部 | 3 | 虚竹 | 23 | 1001 |
| 1001 | 研发部 | 4 | 阿紫 | 18 | 1001 |
| 1002 | 销售部 | 5 | 扫地僧 | 85 | 1002 |
| 1002 | 销售部 | 6 | 李秋水 | 33 | 1002 |
| 1002 | 销售部 | 7 | 鸠摩智 | 50 | 1002 |
+--------+-----------+-----+-----------+------+---------+
-- 查询每个部门的员工数 并升序排序
select d.name,count(*)
from dept d join emp e
on d.deptno = e.dept_id
group by e.dept_id
order by count(*) asc;
+-----------+----------+
| name | count(*) |
+-----------+----------+
| 财务部 | 2 |
| 销售部 | 3 |
| 研发部 | 4 |
+-----------+----------+
-- 查询人数大于等于3的部门 并按照人数降序排序
select d.name,count(*)
from dept d join emp e
on d.deptno = e.dept_id
group by e.dept_id
having count(*) > 3
order by e.dept_id desc;
+-----------+----------+
| name | count(*) |
+-----------+----------+
| 研发部 | 4 |
+-----------+----------+左连接
- 将左表与右表进行连接根据条件进行匹配 如果右表没有匹配的行则返回NULL
- 左连接会保留左表中所有的数据,而右表中没有匹配的数据则用 NULL 值填充
| 属性 | 说明 |
|---|---|
| select * from A表 left join B表 on 条件; | 左链接 |
select * from emp;
+-----+--------------+------+---------+
| eid | ename | age | dept_id |
+-----+--------------+------+---------+
| 1 | 乔峰 | 20 | 1001 |
| 10 | 丁春秋 | 71 | 1005 |
| 2 | 段誉 | 21 | 1001 |
| 3 | 虚竹 | 23 | 1001 |
| 4 | 阿紫 | 18 | 1001 |
| 5 | 扫地僧 | 85 | 1002 |
| 6 | 李秋水 | 33 | 1002 |
| 7 | 鸠摩智 | 50 | 1002 |
| 8 | 天山童姥 | 60 | 1003 |
| 9 | 莫荣博 | 58 | 1003 |
+-----+--------------+------+---------+
-- 查询哪些部门有员工 哪些部门没有员工
select * from dept d left join emp e on d.deptno = e.dept_id;
+--------+-----------+------+--------------+------+---------+
| deptno | name | eid | ename | age | dept_id |
+--------+-----------+------+--------------+------+---------+
| 1001 | 研发部 | 4 | 阿紫 | 18 | 1001 |
| 1001 | 研发部 | 3 | 虚竹 | 23 | 1001 |
| 1001 | 研发部 | 2 | 段誉 | 21 | 1001 |
| 1001 | 研发部 | 1 | 乔峰 | 20 | 1001 |
| 1002 | 销售部 | 7 | 鸠摩智 | 50 | 1002 |
| 1002 | 销售部 | 6 | 李秋水 | 33 | 1002 |
| 1002 | 销售部 | 5 | 扫地僧 | 85 | 1002 |
| 1003 | 财务部 | 9 | 莫荣博 | 58 | 1003 |
| 1003 | 财务部 | 8 | 天山童姥 | 60 | 1003 |
| 1004 | 人事部 | NULL | NULL | NULL | NULL |
+--------+-----------+------+--------------+------+---------+右连接
- 返回两个表中右侧表中的所有记录和左侧表中匹配的记录。如果左表中没有匹配的记录,则在结果集中输出 NULL 值。
| 属性 | 说明 |
|---|---|
| select * from A表 right join B表 on 条件; | 右连接 |
select * from emp;
+-----+--------------+------+---------+
| eid | ename | age | dept_id |
+-----+--------------+------+---------+
| 1 | 乔峰 | 20 | 1001 |
| 10 | 丁春秋 | 71 | 1005 |
| 2 | 段誉 | 21 | 1001 |
| 3 | 虚竹 | 23 | 1001 |
| 4 | 阿紫 | 18 | 1001 |
| 5 | 扫地僧 | 85 | 1002 |
| 6 | 李秋水 | 33 | 1002 |
| 7 | 鸠摩智 | 50 | 1002 |
| 8 | 天山童姥 | 60 | 1003 |
| 9 | 莫荣博 | 58 | 1003 |
+-----+--------------+------+---------+
-- 查询哪些员工有对应部门 哪些没有
select * from dept d right join emp e on d.deptno = e.dept_id;
+--------+-----------+-----+--------------+------+---------+
| deptno | name | eid | ename | age | dept_id |
+--------+-----------+-----+--------------+------+---------+
| 1001 | 研发部 | 1 | 乔峰 | 20 | 1001 |
| NULL | NULL | 10 | 丁春秋 | 71 | 1005 |
| 1001 | 研发部 | 2 | 段誉 | 21 | 1001 |
| 1001 | 研发部 | 3 | 虚竹 | 23 | 1001 |
| 1001 | 研发部 | 4 | 阿紫 | 18 | 1001 |
| 1002 | 销售部 | 5 | 扫地僧 | 85 | 1002 |
| 1002 | 销售部 | 6 | 李秋水 | 33 | 1002 |
| 1002 | 销售部 | 7 | 鸠摩智 | 50 | 1002 |
| 1003 | 财务部 | 8 | 天山童姥 | 60 | 1003 |
| 1003 | 财务部 | 9 | 莫荣博 | 58 | 1003 |
+--------+-----------+-----+--------------+------+---------+union关键字
- NION是一种用于合并两个或多个SELECT语句的操作符。它将来自不同表的结果集组合在一起,并去除重复的行
-- 使用union关键字实现左右连接的并集
select * from dept d left join emp e on d.deptno = e.dept_id
union
select * from dept d right join emp e on d.deptno = e.dept_id;
+--------+-----------+------+--------------+------+---------+
| deptno | name | eid | ename | age | dept_id |
+--------+-----------+------+--------------+------+---------+
| 1001 | 研发部 | 4 | 阿紫 | 18 | 1001 |
| 1001 | 研发部 | 3 | 虚竹 | 23 | 1001 |
| 1001 | 研发部 | 2 | 段誉 | 21 | 1001 |
| 1001 | 研发部 | 1 | 乔峰 | 20 | 1001 |
| 1002 | 销售部 | 7 | 鸠摩智 | 50 | 1002 |
| 1002 | 销售部 | 6 | 李秋水 | 33 | 1002 |
| 1002 | 销售部 | 5 | 扫地僧 | 85 | 1002 |
| 1003 | 财务部 | 9 | 莫荣博 | 58 | 1003 |
| 1003 | 财务部 | 8 | 天山童姥 | 60 | 1003 |
| 1004 | 人事部 | NULL | NULL | NULL | NULL |
| NULL | NULL | 10 | 丁春秋 | 71 | 1005 |
+--------+-----------+------+--------------+------+---------+
-- 使用union all关键字也会将左右连接并集但是不会去重
select * from dept d left join emp e on d.deptno = e.dept_id
union all
select * from dept d right join emp e on d.deptno = e.dept_id;
+--------+-----------+------+--------------+------+---------+
| deptno | name | eid | ename | age | dept_id |
+--------+-----------+------+--------------+------+---------+
| 1001 | 研发部 | 4 | 阿紫 | 18 | 1001 |
| 1001 | 研发部 | 3 | 虚竹 | 23 | 1001 |
| 1001 | 研发部 | 2 | 段誉 | 21 | 1001 |
| 1001 | 研发部 | 1 | 乔峰 | 20 | 1001 |
| 1002 | 销售部 | 7 | 鸠摩智 | 50 | 1002 |
| 1002 | 销售部 | 6 | 李秋水 | 33 | 1002 |
| 1002 | 销售部 | 5 | 扫地僧 | 85 | 1002 |
| 1003 | 财务部 | 9 | 莫荣博 | 58 | 1003 |
| 1003 | 财务部 | 8 | 天山童姥 | 60 | 1003 |
| 1004 | 人事部 | NULL | NULL | NULL | NULL |
| 1001 | 研发部 | 1 | 乔峰 | 20 | 1001 |
| NULL | NULL | 10 | 丁春秋 | 71 | 1005 |
| 1001 | 研发部 | 2 | 段誉 | 21 | 1001 |
| 1001 | 研发部 | 3 | 虚竹 | 23 | 1001 |
| 1001 | 研发部 | 4 | 阿紫 | 18 | 1001 |
| 1002 | 销售部 | 5 | 扫地僧 | 85 | 1002 |
| 1002 | 销售部 | 6 | 李秋水 | 33 | 1002 |
| 1002 | 销售部 | 7 | 鸠摩智 | 50 | 1002 |
| 1003 | 财务部 | 8 | 天山童姥 | 60 | 1003 |
| 1003 | 财务部 | 9 | 莫荣博 | 58 | 1003 |
+--------+-----------+------+--------------+------+---------+子查询
- 子查询是一个嵌套在其他查询语句中的查询,它可以作为主查询或其他子查询的一部分。子查询可以用于检索满足特定条件的数据,这些条件可能无法使用单个简单的查询完成。
- 子查询也可以结合关键字使用
-- 查询最大年龄的员工信息,显示信息包含员工工号、名字、年龄
-- 使用子查询先查最大年龄在进行嵌套
-- 最大年龄 select max(age) from emp;
select * from emp where age = (select max(age) from emp);
+-----+-----------+------+---------+
| eid | ename | age | dept_id |
+-----+-----------+------+---------+
| 5 | 扫地僧 | 85 | 1002 |
+-----+-----------+------+---------+
-- 查询研发部和销售部的员工信息 包含员工号、名字
-- 1. 先查询部门
select deptno from dept where name in('研发部','销售部');
+--------+
| deptno |
+--------+
| 1001 |
| 1002 |
+--------+
-- 2.查询哪些员工部门号是1001和1002
select * from emp where dept_id in(1001,1002);
+-----+--------------+------+---------+
| eid | ename | age | dept_id |
+-----+--------------+------+---------+
| 5 | 扫地僧 | 85 | 1002 |
| 6 | 李秋水 | 33 | 1002 |
| 7 | 鸠摩智 | 50 | 1002 |
| 8 | 天山童姥 | 60 | 1003 |
| 9 | 莫荣博 | 58 | 1003 |
+-----+--------------+------+---------+
-- 子查询
select * from emp where dept_id in(select deptno from dept where name in('研发部','销售部'));
+-----+-----------+------+---------+
| eid | ename | age | dept_id |
+-----+-----------+------+---------+
| 1 | 乔峰 | 20 | 1001 |
| 2 | 段誉 | 21 | 1001 |
| 3 | 虚竹 | 23 | 1001 |
| 4 | 阿紫 | 18 | 1001 |
| 5 | 扫地僧 | 85 | 1002 |
| 6 | 李秋水 | 33 | 1002 |
| 7 | 鸠摩智 | 50 | 1002 |
+-----+-----------+------+---------+
-- 查询研发部30岁以下的员工信息,包括员工号、名字、部门名字
-- 方式1 关联查询
select * from dept d join emp e on d.deptno = e.dept_id and (name = '研发部' and age<20);
+--------+-----------+-----+--------+------+---------+
| deptno | name | eid | ename | age | dept_id |
+--------+-----------+-----+--------+------+---------+
| 1001 | 研发部 | 4 | 阿紫 | 18 | 1001 |
+--------+-----------+-----+--------+------+---------+
-- 方式2 子查询
-- 1.先查询部门
select * from dept where name = '研发部';
-- 2.再查询年龄小于30岁
select * from emp where age < 30;
-- 3.使用内连接将两个表连接起来
mysql> select * from
-> (select * from dept where name = '研发部') t1
-> join (select * from emp where age < 30) t2
-> on t1.deptno = t2.dept_id;
+--------+-----------+-----+--------+------+---------+
| deptno | name | eid | ename | age | dept_id |
+--------+-----------+-----+--------+------+---------+
| 1001 | 研发部 | 1 | 乔峰 | 20 | 1001 |
| 1001 | 研发部 | 2 | 段誉 | 21 | 1001 |
| 1001 | 研发部 | 3 | 虚竹 | 23 | 1001 |
| 1001 | 研发部 | 4 | 阿紫 | 18 | 1001 |
+--------+-----------+-----+--------+------+---------+ ALL关键字
- 用于比较子查询返回的所有结果与外部查询中的值。
| 属性 | 说明 |
|---|---|
| select ...from ...where 字段 all (查询语句); |
- 具体来说, "select"关键字指示要选择哪些列,"from"关键字指示要从哪个表中选择数据,"where"关键字指示要筛选哪些行,">all"是比较运算符,表示要筛选出字段大于查询结果集中所有值的最大值的行,括号内的查询语句指定了要比较的值集合。
select * from emp;
+-----+--------------+------+---------+
| eid | ename | age | dept_id |
+-----+--------------+------+---------+
| 1 | 乔峰 | 20 | 1001 |
| 10 | 丁春秋 | 71 | 1005 |
| 2 | 段誉 | 21 | 1001 |
| 3 | 虚竹 | 23 | 1001 |
| 4 | 阿紫 | 18 | 1001 |
| 5 | 扫地僧 | 85 | 1002 |
| 6 | 李秋水 | 33 | 1002 |
| 7 | 鸠摩智 | 50 | 1002 |
| 8 | 天山童姥 | 60 | 1003 |
| 9 | 莫荣博 | 58 | 1003 |
+-----+--------------+------+---------+
-- 查询年龄是1003的员工信息
select age from emp where dept_id = '1003';
+------+
| age |
+------+
| 60 |
| 58 |
+------+
-- 查询年龄大于1003部门所有年龄的员工信息
select * from emp where age > all(select age from emp where dept_id = '1003');
+-----+-----------+------+---------+
| eid | ename | age | dept_id |
+-----+-----------+------+---------+
| 10 | 丁春秋 | 71 | 1005 |
| 5 | 扫地僧 | 85 | 1002 |
+-----+-----------+------+---------+
-- 查询不属于任何一个部门的员工信息
-- 1.查看部门表的所有部门号
select deptno from dept;
+--------+
| deptno |
+--------+
| 1001 |
| 1002 |
| 1003 |
| 1004 |
+--------+
-- 2.查询不属于任何一个部门的员工信息
select * from emp where dept_id != all(select deptno from dept);
+-----+-----------+------+---------+
| eid | ename | age | dept_id |
+-----+-----------+------+---------+
| 10 | 丁春秋 | 71 | 1005 |
+-----+-----------+------+---------+ANY和SOME关键字
- ANY/SOME:查询结果与子查询结果进行比较 返回任意个匹配的结果 。
| 属性 | 说明 |
|---|---|
| select ... from 表 where 字段 any(子查询); |
-- 查询年龄大于1003部门任意 一个员工年龄的员工信息
-- 1.查看员工为1003部门号的员工年龄
select age from emp where dept_id =1003;
+------+
| age |
+------+
| 60 |
| 58 |
+------+
-- 2.查询所有大于员工为1003部门号的任意一个 any(60,58) 满足其中一个就为true
select * from emp where age > any(select age from emp where dept_id =1003) and dept_id != 1003;
+-----+-----------+------+---------+
| eid | ename | age | dept_id |
+-----+-----------+------+---------+
| 10 | 丁春秋 | 71 | 1005 |
| 5 | 扫地僧 | 85 | 1002 |
+-----+-----------+------+---------+IN关键字
- 判断某个记录的值 是否在指定的集合中
-- 查询研发部和销售部的员工信息 包含员工号 员工名字
-- 1.先查询部门研发部和销售部的部门号
select deptno from dept where name in('研发部','销售部');
+--------+
| deptno |
+--------+
| 1001 |
| 1002 |
+--------+
-- 2.在查询部门的员工表是否包含部门号信息
select * from emp where dept_id in (select deptno from dept where name in('研发部','销售部'));
+-----+-----------+------+---------+
| eid | ename | age | dept_id |
+-----+-----------+------+---------+
| 1 | 乔峰 | 20 | 1001 |
| 2 | 段誉 | 21 | 1001 |
| 3 | 虚竹 | 23 | 1001 |
| 4 | 阿紫 | 18 | 1001 |
| 5 | 扫地僧 | 85 | 1002 |
| 6 | 李秋水 | 33 | 1002 |
| 7 | 鸠摩智 | 50 | 1002 |
+-----+-----------+------+---------+EXISTS关键字
- EXISTS后面有结果外层至少返回以行数据 如果没有结果 外层不返回数据
- EXISTS最好跟别名使用查询更清晰易懂
- 如果数据量比较大的时候使用exists
| 属性 | 说明 |
|---|---|
| select ... from where exists(查询语句); |
-- 查询公司是否有大于60岁的员工 有就输出
-- 用别名表 根据查询到的结果进行判断 如果有则返回别名表中的数据 不使用别名会返回全部的数据
select * from emp e where exists(select * from emp where e.age >60);
+-----+-----------+------+---------+
| eid | ename | age | dept_id |
+-----+-----------+------+---------+
| 10 | 丁春秋 | 71 | 1005 |
| 5 | 扫地僧 | 85 | 1002 |
+-----+-----------+------+---------+
-- 查询有所属部门的员工信息 除了1005部门其他的都显示
select * from emp e where exists(
select * from dept d where e.dept_id = d.deptno);
+-----+--------------+------+---------+
| eid | ename | age | dept_id |
+-----+--------------+------+---------+
| 1 | 乔峰 | 20 | 1001 |
| 2 | 段誉 | 21 | 1001 |
| 3 | 虚竹 | 23 | 1001 |
| 4 | 阿紫 | 18 | 1001 |
| 5 | 扫地僧 | 85 | 1002 |
| 6 | 李秋水 | 33 | 1002 |
| 7 | 鸠摩智 | 50 | 1002 |
| 8 | 天山童姥 | 60 | 1003 |
| 9 | 莫荣博 | 58 | 1003 |
+-----+--------------+------+---------+自关联查询
- 在同一表内进行连接操作,将表中的一列与同一表中的另一列相比较
-- 创建一个家庭地位表
create table family_status(
id int primary key, -- 排名
ename varchar(20), -- 成员信息
status_number int, -- 地位编号
foreign key (status_number) references family_status(id) -- 自关联约束
);
-- 添加数据
insert into family_status values(1,'妈妈',null);
insert into family_status values(2,'爸爸',1);
insert into family_status values(3,'哥哥',2);
insert into family_status values(4,'弟弟',3);
insert into family_status values(5,'妹妹',3);
insert into family_status values(6,'姐姐',2);
-- 查询表的内容
select * from family_status a,family_status b;
+----+--------+---------------+----+--------+---------------+
| id | ename | status_number | id | ename | status_number |
+----+--------+---------------+----+--------+---------------+
| 6 | 姐姐 | 2 | 1 | 妈妈 | NULL |
| 5 | 妹妹 | 3 | 1 | 妈妈 | NULL |
| 4 | 弟弟 | 3 | 1 | 妈妈 | NULL |
| 3 | 哥哥 | 2 | 1 | 妈妈 | NULL |
| 2 | 爸爸 | 1 | 1 | 妈妈 | NULL |
| 1 | 妈妈 | NULL | 1 | 妈妈 | NULL |
| 6 | 姐姐 | 2 | 2 | 爸爸 | 1 |
| 5 | 妹妹 | 3 | 2 | 爸爸 | 1 |
| 4 | 弟弟 | 3 | 2 | 爸爸 | 1 |
| 3 | 哥哥 | 2 | 2 | 爸爸 | 1 |
| 2 | 爸爸 | 1 | 2 | 爸爸 | 1 |
| 1 | 妈妈 | NULL | 2 | 爸爸 | 1 |
| 6 | 姐姐 | 2 | 3 | 哥哥 | 2 |
| 5 | 妹妹 | 3 | 3 | 哥哥 | 2 |
| 4 | 弟弟 | 3 | 3 | 哥哥 | 2 |
| 3 | 哥哥 | 2 | 3 | 哥哥 | 2 |
| 2 | 爸爸 | 1 | 3 | 哥哥 | 2 |
| 1 | 妈妈 | NULL | 3 | 哥哥 | 2 |
| 6 | 姐姐 | 2 | 4 | 弟弟 | 3 |
| 5 | 妹妹 | 3 | 4 | 弟弟 | 3 |
| 4 | 弟弟 | 3 | 4 | 弟弟 | 3 |
| 3 | 哥哥 | 2 | 4 | 弟弟 | 3 |
| 2 | 爸爸 | 1 | 4 | 弟弟 | 3 |
| 1 | 妈妈 | NULL | 4 | 弟弟 | 3 |
| 6 | 姐姐 | 2 | 5 | 妹妹 | 3 |
| 5 | 妹妹 | 3 | 5 | 妹妹 | 3 |
| 4 | 弟弟 | 3 | 5 | 妹妹 | 3 |
| 3 | 哥哥 | 2 | 5 | 妹妹 | 3 |
| 2 | 爸爸 | 1 | 5 | 妹妹 | 3 |
| 1 | 妈妈 | NULL | 5 | 妹妹 | 3 |
| 6 | 姐姐 | 2 | 6 | 姐姐 | 2 |
| 5 | 妹妹 | 3 | 6 | 姐姐 | 2 |
| 4 | 弟弟 | 3 | 6 | 姐姐 | 2 |
| 3 | 哥哥 | 2 | 6 | 姐姐 | 2 |
| 2 | 爸爸 | 1 | 6 | 姐姐 | 2 |
| 1 | 妈妈 | NULL | 6 | 姐姐 | 2 |
+----+--------+---------------+----+--------+---------------+
-- 查询每个成员的关系地位
select * from family_status a, family_status b
where a.status_number = b.id;
+----+--------+---------------+----+--------+---------------+
| id | ename | status_number | id | ename | status_number |
+----+--------+---------------+----+--------+---------------+
| 2 | 爸爸 | 1 | 1 | 妈妈 | NULL |
| 3 | 哥哥 | 2 | 2 | 爸爸 | 1 |
| 4 | 弟弟 | 3 | 3 | 哥哥 | 2 |
| 5 | 妹妹 | 3 | 3 | 哥哥 | 2 |
| 6 | 姐姐 | 2 | 2 | 爸爸 | 1 |
+----+--------+---------------+----+--------+---------------+
-- 2.查询所有成员的上级 只有名字
select a.ename,b.ename from family_status a
left join family_status b
on a.status_number = b.id;
+--------+--------+
| ename | ename |
+--------+--------+
| 妈妈 | NULL |
| 爸爸 | 妈妈 |
| 哥哥 | 爸爸 |
| 弟弟 | 哥哥 |
| 妹妹 | 哥哥 |
| 姐姐 | 爸爸 |
+--------+--------+
-- 3.查询 姐姐 哥哥 妹妹的上级
select * from family_status a,
family_status b
where a.status_number = b.id
and a.ename in('哥哥','妹妹','姐姐');
+----+--------+---------------+----+--------+---------------+
| id | ename | status_number | id | ename | status_number |
+----+--------+---------------+----+--------+---------------+
| 3 | 哥哥 | 2 | 2 | 爸爸 | 1 |
| 5 | 妹妹 | 3 | 3 | 哥哥 | 2 |
| 6 | 姐姐 | 2 | 2 | 爸爸 | 1 |
+----+--------+---------------+----+--------+---------------+
mysql> select * from family_status a,family_status b where a.status_number = b.id;
+----+--------+---------------+----+--------+---------------+
| id | ename | status_number | id | ename | status_number |
+----+--------+---------------+----+--------+---------------+
| 2 | 爸爸 | 1 | 1 | 妈妈 | NULL |
| 3 | 哥哥 | 2 | 2 | 爸爸 | 1 |
| 4 | 弟弟 | 3 | 3 | 哥哥 | 2 |
| 5 | 妹妹 | 3 | 3 | 哥哥 | 2 |
| 6 | 姐姐 | 2 | 2 | 爸爸 | 1 |
+----+--------+---------------+----+--------+---------------+
5 rows in set (0.00 sec)
mysql> select a.ename,b.ename from family_status a,family_status b where a.status_number = b.id;
+--------+--------+
| ename | ename |
+--------+--------+
| 爸爸 | 妈妈 |
| 哥哥 | 爸爸 |
| 弟弟 | 哥哥 |
| 妹妹 | 哥哥 |
| 姐姐 | 爸爸 |
+--------+--------+多表操作总结
函数
- 函数是一种可重复使用的程序单元,它接受一个或多个输入参数,并返回一个值作为结果。函数可以用于执行各种操作,包括数学计算、字符串操作、日期处理等等。在SQL语言中,有内置函数和用户定义函数两种类型。
聚合函数
- group_concat是一种SQL函数,它用于将组中的多个行合并为单个字符串。它将每个行的特定列连接成单个字符串,并在每个值之间插入一个分隔符。
- 聚合函数包括count(统计函数)、sum(求和)、max(最大值)、min(最小值)、avg(平均值)等等
| 属性 | 说明 |
|---|---|
| select group_concat(合并字段) from 表; |
create database mydb1;
use mydb1;
-- 创建一个部门表
create table emp(
emp_id int primary key auto_increment comment '编号',
emp_name char(20) not null default '' comment '姓名',
salary decimal(10,2) not null default 0 comment '工资',
department char(20) not null default '' comment '部门'
);
insert into emp values(null,'张晶晶',5000,'财务部');
insert into emp values(null,'王飞飞',5800,'财务部');
insert into emp values(null,'赵刚',6200,'财务部');
insert into emp values(null,'刘小贝',5700,'人事部');
insert into emp values(null,'王大鹏',6700,'人事部');
insert into emp values(null,'张小裴',5200,'人事部');
insert into emp values(null,'刘云云',7500,'销售部');
insert into emp values(null,'刘云鹏',7200,'销售部');
insert into emp values(null,'刘云鹏',7800,'销售部');
-- 将所有的员工名字合并成一行
select group_concat(emp_name) from emp;
+----------------------------------------------------------------------------------------+
| group_concat(emp_name) |
+----------------------------------------------------------------------------------------+
| 张晶晶,王飞飞,赵刚,刘小贝,王大鹏,张小裴,刘云云,刘云鹏,刘云鹏 |
+----------------------------------------------------------------------------------------+
-- 指定分隔符合并
select group_concat(emp_name separator ";") from emp;
+----------------------------------------------------------------------------------------+
| group_concat(emp_name separator ";") |
+----------------------------------------------------------------------------------------+
| 张晶晶;王飞飞;赵刚;刘小贝;王大鹏;张小裴;刘云云;刘云鹏;刘云鹏 |
+----------------------------------------------------------------------------------------+
-- 指定排序方式和分隔符
select group_concat(emp_name separator ";") from emp group by department;
+--------------------------------------+
| group_concat(emp_name separator ";") |
+--------------------------------------+
| 刘小贝;王大鹏;张小裴 |
| 张晶晶;王飞飞;赵刚 |
| 刘云云;刘云鹏;刘云鹏 |
+--------------------------------------+
-- 指定分隔符和排序方式按照工资从高到低降序排序
select group_concat(emp_name order by salary desc separator ";") from emp group by department;
+-----------------------------------------------------------+
| group_concat(emp_name order by salary desc separator ";") |
+-----------------------------------------------------------+
| 王大鹏;刘小贝;张小裴 |
| 赵刚;王飞飞;张晶晶 |
| 刘云鹏;刘云云;刘云鹏 |
+-----------------------------------------------------------+数学函数
- 数学函数是一种关系,它将一个或多个输入值映射到一个输出值
| 属性 | 说明 |
|---|---|
| abs | 返回绝对值 |
| ceil | 向上取整 |
| floor | 向下取整 |
| greatest(1,2,3) | 取列表最大值 |
| least(1,2,3) | 取最小值 |
| mod | 取模 |
| power | 取x的y次方 |
| rand() | 取随机数 |
| round | 取四舍五入的小数 |
-- 取绝对值
select abs(-10);
+----------+
| abs(-10) |
+----------+
| 10 |
+----------+
-- 向上取整
select ceil(salary) from emp;
+--------------+
| ceil(salary) |
+--------------+
| 5000 |
| 5800 |
| 6200 |
| 5700 |
| 6700 |
| 5200 |
| 7500 |
| 7200 |
| 7800 |
+--------------+
-- 向下取整
select floor(1.5);
+------------+
| floor(1.5) |
+------------+
| 1 |
+------------+
-- 取模
select mod(10,3);
+-----------+
| mod(10,3) |
+-----------+
| 1 |
+-----------+
-- 取次方
select power(2,3);
+------------+
| power(2,3) |
+------------+
| 8 |
+------------+
-- 取随机数
select rand();
+---------------------+
| rand() |
+---------------------+
| 0.12785046093897007 |
+---------------------+
-- 取10以内的随机数
select ceil(rand()*10);
+-----------------+
| ceil(rand()*10) |
+-----------------+
| 5 |
+-----------------+
-- 四舍五入
select round(15.56);
+--------------+
| round(15.56) |
+--------------+
| 16 |
+--------------+字符函数
- 字符函数是一类用于处理字符串数据类型的函数。
| 属性 | 说明 |
|---|---|
| char_length | 返回字符串的个数 |
| length | 返回字节长度 |
| concat | 拼接字符串 |
| concat_ws('分隔符',str,str) | 指定分隔符拼接字符串 |
| field | 返回字符串在列表中的位置 |
| ltrim | 去除字符串左边空格 |
| rtim | 去除字符串右边空格 |
| trim | 去除两边空格 |
| mid('helloworld',2,3) | 字符串截取 从第二开始截取3个字符 |
| position('abc' in 'blogdxabc') | 获取字符串A在字符串中出现的位置 |
| replace('hello','e','b') | 字符串替换 |
| reverse('hello') | 字符串翻转 |
| right('hello',3) | 返回字符串后三个字符 |
| strcmp(s1,s2) | 相等0 s1>s2 返回1 否-1 |
| substr('helloworld',2,3) | 字符串截取 从第二开始截取3个字符 |
| ucase、upper | 小写转换大写 |
| lcase、lower | 大写转换小写 |
-- 学生表
create table student(
id int primary key auto_increment,
sname varchar(20),
age int,
score double,
hiredate date
);
-- 插入数据
insert into student values(null,'张三',18,87.6,'2005-10-15');
insert into student values(null,'李四',19,91.5,'2004-10-15');
insert into student values(null,'王五',20,78.1,'2003-10-15');
insert into student values(null,'赵六',21,84.6,'2002-10-15');
-- 获取分数对分数取整
select floor(score) from student;
+--------------+
| floor(score) |
+--------------+
| 87 |
| 91 |
| 78 |
| 84 |
+--------------+
-- 获取每个学生的出生年份
select sname, substr(hiredate,1,4) '年' from student;
+--------+------+
| sname | 年 |
+--------+------+
| 张三 | 2005 |
| 李四 | 2004 |
| 王五 | 2003 |
| 赵六 | 2002 |
+--------+------+日期函数
- 日期函数可以用于获取当前日期和时间、将日期和时间格式化为指定的字符串、从日期和时间中提取特定部分(例如年、月、日、小时、分钟等)以及对日期和时间进行算术计算等操作
| 属性 | 说明 |
|---|---|
| unix_timestamp | 获取时间戳(毫秒值) |
| select now() | 返回当前日期和时间 |
| unix_timestamp('2001-10-17 08:00:00') | 将日期转换为毫秒值 |
| from_unixtime(1003276800,'%Y-%m-%d %H:%i:%s') | 将时间戳毫秒转换为指定格式日期 |
| current_time() | 获取时间 时分秒 |
| date('2023-01-14 12:31:56') | 从日期返回年月日 |
| datediff(now(),'2023-04-16') | 计算当前日期(now())与指定日期('2023-04-16')之间相差的天数。 |
| date_format('2021-1-1 1:1:1','%Y-%m-%d %H:%i:%s'); | 格式化日期 |
| str_to_date('2021-1-1 1:1:1','%Y-%m-%d %H:%i:%s'); | 字符串转换为日期 |
| date_sub('2023-06-17',interval 2 day) | 当前日期减两天 |
| date_add('2023-06-17',interval 2 day) | 当前日期加两天 |
| select extract(hour from '2021-12-13 11:14:12'); | 从日期获取小时hour |
-- 获取当前时间
select now();
+---------------------+
| now() |
+---------------------+
| 2023-04-17 20:55:17 |
+---------------------+
-- 将日期转换为毫秒
select unix_timestamp('2001-10-17 08:00:00');
+---------------------------------------+
| unix_timestamp('2001-10-17 08:00:00') |
+---------------------------------------+
| 1003276800 |
+---------------------------------------+
-- 获取时分秒
select current_time();
+----------------+
| current_time() |
+----------------+
| 20:56:24 |
+----------------+
-- 出生到现在已经过了
select datediff(now(),'2001-10-17');
+------------------------------+
| datediff(now(),'2001-10-17') |
+------------------------------+
| 7852 |
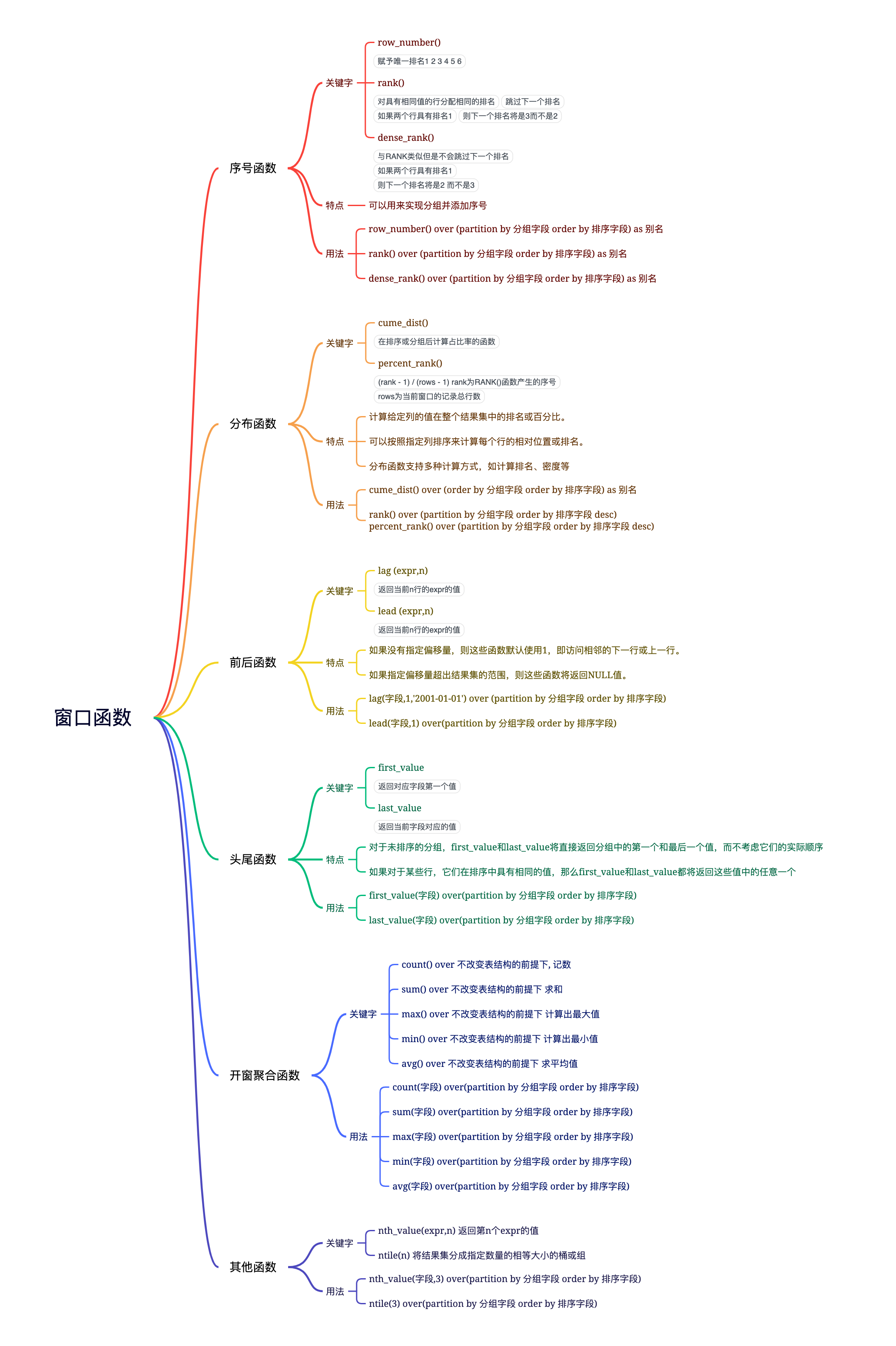
+------------------------------+窗口函数
- 数据库中的窗口函数是一种特殊的函数,它可以在查询结果集中创建一个“窗口”,并针对该窗口内的行执行聚合、排序、排名等操作。例如,常见的窗口函数包括 RANK()、ROW_NUMBER()、LEAD() 和 LAG() 等。它们可以用来实现各种高级查询和分析操作,如数据分组、移动平均线计算、累计求和等。
- 以下都是基于 分组 排序进行查询的 over(partition by 分组 order by 排序), 这是一个字段
序号函数
- 可以用来实现分组排序,并添加序号
- ROW_NUMBER():顺序排序1、2、3
- RANK():并列排序,跳过重复序号1、1、3
- DENSE_RANK():并列排序,不跳过重复序号1、1、2
| 属性 | 说明 |
|---|---|
| select 字段1,字段2... row_number() over(partition by 分组字段 order by 排序字段 desc) | 顺序排序 |
| select 字段1,字段2... rank() over(partition by 分组字段 order by 排序字段 desc) | 并列排序,跳过重复序号 |
| select 字段1,字段2... dense_rank() over(partition by 分组字段 order by 排序字段 desc) | 并列排序,不跳过重复序号 |
-- 创建一个库
create database mydb2;
use mydb2;
-- 创建一个表
create table employee(
dname varchar(20), -- 部门名
eid varchar(20),
ename varchar(20),
hiredate date, -- 入职日期
salary double -- 薪资
);
-- 插入数据
insert into employee values('研发部','1001','刘备','2021-11-01',3000);
insert into employee values('研发部','1002','关羽','2021-11-02',5000);
insert into employee values('研发部','1003','张飞','2021-11-03',7000);
insert into employee values('研发部','1004','赵云','2021-11-04',7000);
insert into employee values('研发部','1005','马超','2021-11-05',4000);
insert into employee values('研发部','1006','黄忠','2021-11-06',4000);
insert into employee values('销售部','1007','曹操','2021-11-01',2000);
insert into employee values('销售部','1008','许褚','2021-11-02',3000);
insert into employee values('销售部','1009','典韦','2021-11-03',5000);
insert into employee values('销售部','1010','张辽','2021-11-04',6000);
insert into employee values('销售部','1011','虚晃','2021-11-05',9000);
insert into employee values('销售部','1012','曹洪','2021-11-06',6000);
-- 对每个部门的员工按照薪资排序,并给出排名
select dname,ename,salary,
row_number() over(partition by dname order by salary desc) as rn
from employee;
+-----------+--------+--------+----+
| dname | ename | salary | rn |
+-----------+--------+--------+----+
| 研发部 | 张飞 | 7000 | 1 |
| 研发部 | 赵云 | 7000 | 2 |
| 研发部 | 关羽 | 5000 | 3 |
| 研发部 | 马超 | 4000 | 4 |
| 研发部 | 黄忠 | 4000 | 5 |
| 研发部 | 刘备 | 3000 | 6 |
| 销售部 | 虚晃 | 9000 | 1 |
| 销售部 | 张辽 | 6000 | 2 |
| 销售部 | 曹洪 | 6000 | 3 |
| 销售部 | 典韦 | 5000 | 4 |
| 销售部 | 许褚 | 3000 | 5 |
| 销售部 | 曹操 | 2000 | 6 |
+-----------+--------+--------+----+
select *,
row_number() over(partition by dname order by salary desc) rn,
rank() over(partition by dname order by salary desc) rn1,
dense_rank() over(partition by dname order by salary desc) rn2
from employee;
+-----------+--------+--------+----+-----+-----+
| dname | ename | salary | rn | rn1 | rn2 |
+-----------+--------+--------+----+-----+-----+
| 研发部 | 张飞 | 7000 | 1 | 1 | 1 |
| 研发部 | 赵云 | 7000 | 2 | 1 | 1 |
| 研发部 | 关羽 | 5000 | 3 | 3 | 2 |
| 研发部 | 马超 | 4000 | 4 | 4 | 3 |
| 研发部 | 黄忠 | 4000 | 5 | 4 | 3 |
| 研发部 | 刘备 | 3000 | 6 | 6 | 4 |
| 销售部 | 虚晃 | 9000 | 1 | 1 | 1 |
| 销售部 | 张辽 | 6000 | 2 | 2 | 2 |
| 销售部 | 曹洪 | 6000 | 3 | 2 | 2 |
| 销售部 | 典韦 | 5000 | 4 | 4 | 3 |
| 销售部 | 许褚 | 3000 | 5 | 5 | 4 |
| 销售部 | 曹操 | 2000 | 6 | 6 | 5 |
+-----------+--------+--------+----+-----+-----+
-- 求每个部门薪资排在前三名的员工对其进行分组
select * from
(select dname,ename,salary,
dense_rank() over(partition by dname order by salary desc) as rn
from employee) a
where a.rn <=3;
+-----------+--------+--------+----+
| dname | ename | salary | rn |
+-----------+--------+--------+----+
| 研发部 | 张飞 | 7000 | 1 |
| 研发部 | 赵云 | 7000 | 1 |
| 研发部 | 关羽 | 5000 | 2 |
| 研发部 | 马超 | 4000 | 3 |
| 研发部 | 黄忠 | 4000 | 3 |
| 销售部 | 虚晃 | 9000 | 1 |
| 销售部 | 张辽 | 6000 | 2 |
| 销售部 | 曹洪 | 6000 | 2 |
| 销售部 | 典韦 | 5000 | 3 |
+-----------+--------+--------+----+
-- 对所有员工进行全局排序 不分组
select dname,ename,salary,
dense_rank() over (order by salary desc) as ru from employee;
+-----------+--------+--------+----+
| dname | ename | salary | ru |
+-----------+--------+--------+----+
| 销售部 | 虚晃 | 9000 | 1 |
| 研发部 | 张飞 | 7000 | 2 |
| 研发部 | 赵云 | 7000 | 2 |
| 销售部 | 张辽 | 6000 | 3 |
| 销售部 | 曹洪 | 6000 | 3 |
| 研发部 | 关羽 | 5000 | 4 |
| 销售部 | 典韦 | 5000 | 4 |
| 研发部 | 马超 | 4000 | 5 |
| 研发部 | 黄忠 | 4000 | 5 |
| 研发部 | 刘备 | 3000 | 6 |
| 销售部 | 许褚 | 3000 | 6 |
| 销售部 | 曹操 | 2000 | 7 |
+-----------+--------+--------+----+开窗聚合函数
- 聚合窗口函数是对分组后的数据进行计算(求和、最大、最小、平均值、行)并返回结果。
select sum(salary) sum from employee;
+-------+
| sum |
+-------+
| 61000 |
+-------+
select *, sum(salary) over(partition by dname order by eid) as '和',
avg(salary) over(partition by dname order by eid) as '平均值',
count(salary) over(partition by dname order by eid) as '行',
max(salary) over(partition by dname order by eid) as '最大值',
min(salary) over(partition by dname order by eid) as '最小值'
from employee;
+-----------+------+--------+------------+--------+-------+--------------------+-----+-----------+-----------+
| dname | eid | ename | hiredate | salary | 和 | 平均值 | 行 | 最大值 | 最小值 |
+-----------+------+--------+------------+--------+-------+--------------------+-----+-----------+-----------+
| 研发部 | 1001 | 刘备 | 2021-11-01 | 3000 | 3000 | 3000 | 1 | 3000 | 3000 |
| 研发部 | 1002 | 关羽 | 2021-11-02 | 5000 | 8000 | 4000 | 2 | 5000 | 3000 |
| 研发部 | 1003 | 张飞 | 2021-11-03 | 7000 | 15000 | 5000 | 3 | 7000 | 3000 |
| 研发部 | 1004 | 赵云 | 2021-11-04 | 7000 | 22000 | 5500 | 4 | 7000 | 3000 |
| 研发部 | 1005 | 马超 | 2021-11-05 | 4000 | 26000 | 5200 | 5 | 7000 | 3000 |
| 研发部 | 1006 | 黄忠 | 2021-11-06 | 4000 | 30000 | 5000 | 6 | 7000 | 3000 |
| 销售部 | 1007 | 曹操 | 2021-11-01 | 2000 | 2000 | 2000 | 1 | 2000 | 2000 |
| 销售部 | 1008 | 许褚 | 2021-11-02 | 3000 | 5000 | 2500 | 2 | 3000 | 2000 |
| 销售部 | 1009 | 典韦 | 2021-11-03 | 5000 | 10000 | 3333.3333333333335 | 3 | 5000 | 2000 |
| 销售部 | 1010 | 张辽 | 2021-11-04 | 6000 | 16000 | 4000 | 4 | 6000 | 2000 |
| 销售部 | 1011 | 虚晃 | 2021-11-05 | 9000 | 25000 | 5000 | 5 | 9000 | 2000 |
| 销售部 | 1012 | 曹洪 | 2021-11-06 | 6000 | 31000 | 5166.666666666667 | 6 | 9000 | 2000 |
+-----------+------+--------+------------+--------+-------+--------------------+-----+-----------+-----------+
-- 将表按部门名称进行分组,并按入职日期排序,计算员工所在部门的累计薪水总和a。
select dname,ename,salary, hiredate,
sum(salary)
over(partition by dname order by hiredate) a
from employee;
+-----------+--------+--------+------------+-------+
| dname | ename | salary | hiredate | a |
+-----------+--------+--------+------------+-------+
| 研发部 | 刘备 | 3000 | 2021-11-01 | 3000 | -- 这个和是从第一个行开始加到当前的行
| 研发部 | 关羽 | 5000 | 2021-11-02 | 8000 |
| 研发部 | 张飞 | 7000 | 2021-11-03 | 15000 |
| 研发部 | 赵云 | 7000 | 2021-11-04 | 22000 |
| 研发部 | 马超 | 4000 | 2021-11-05 | 26000 |
| 研发部 | 黄忠 | 4000 | 2021-11-06 | 30000 | -- 3000+5000+7000+...= 30000
| 销售部 | 曹操 | 2000 | 2021-11-01 | 2000 |
| 销售部 | 许褚 | 3000 | 2021-11-02 | 5000 |
| 销售部 | 典韦 | 5000 | 2021-11-03 | 10000 |
| 销售部 | 张辽 | 6000 | 2021-11-04 | 16000 |
| 销售部 | 虚晃 | 9000 | 2021-11-05 | 25000 |
| 销售部 | 曹洪 | 6000 | 2021-11-06 | 31000 |
+-----------+--------+--------+------------+-------+
-- 将表按部门名称进行分组,并按入职日期排序,计算员工所在部门的累计薪水总和。 不加order by 会把分组内的所有数据进行求和
select dname,ename,salary, hiredate,
sum(salary)
over(partition by dname) a
from employee;
+-----------+--------+--------+------------+-------+
| dname | ename | salary | hiredate | a |
+-----------+--------+--------+------------+-------+
| 研发部 | 刘备 | 3000 | 2021-11-01 | 30000 |
| 研发部 | 关羽 | 5000 | 2021-11-02 | 30000 |
| 研发部 | 张飞 | 7000 | 2021-11-03 | 30000 |
| 研发部 | 赵云 | 7000 | 2021-11-04 | 30000 |
| 研发部 | 马超 | 4000 | 2021-11-05 | 30000 |
| 研发部 | 黄忠 | 4000 | 2021-11-06 | 30000 |
| 销售部 | 曹操 | 2000 | 2021-11-01 | 31000 |
| 销售部 | 许褚 | 3000 | 2021-11-02 | 31000 |
| 销售部 | 典韦 | 5000 | 2021-11-03 | 31000 |
| 销售部 | 张辽 | 6000 | 2021-11-04 | 31000 |
| 销售部 | 虚晃 | 9000 | 2021-11-05 | 31000 |
| 销售部 | 曹洪 | 6000 | 2021-11-06 | 31000 |
+-----------+--------+--------+------------+-------+
-- 对部门进行分组 日期进行排序并计算出在当前行及其前三行之间的薪水总和(c1)
select dname,ename,salary,
sum(salary)
over(partition by dname order by hiredate rows between 3 preceding and current row) c1
from employee;
+-----------+--------+--------+-------+
| dname | ename | salary | c1 |
+-----------+--------+--------+-------+
| 研发部 | 刘备 | 3000 | 3000 |
| 研发部 | 关羽 | 5000 | 8000 |
| 研发部 | 张飞 | 7000 | 15000 |
| 研发部 | 赵云 | 7000 | 22000 |
| 研发部 | 马超 | 4000 | 23000 |
| 研发部 | 黄忠 | 4000 | 22000 |
| 销售部 | 曹操 | 2000 | 2000 |
| 销售部 | 许褚 | 3000 | 5000 |
| 销售部 | 典韦 | 5000 | 10000 |
| 销售部 | 张辽 | 6000 | 16000 |
| 销售部 | 虚晃 | 9000 | 23000 |
| 销售部 | 曹洪 | 6000 | 26000 |
+-----------+--------+--------+-------+
-- 对部门进行分组 日期进行排序 并计算出向前三行以及当前行的薪水总和c1
select dname,ename,salary,
sum(salary) over(partition by dname order by hiredate rows between 3 preceding and 1 following) c1
from employee;
+-----------+--------+--------+-------+
| dname | ename | salary | c1 |
+-----------+--------+--------+-------+
| 研发部 | 刘备 | 3000 | 8000 |
| 研发部 | 关羽 | 5000 | 15000 |
| 研发部 | 张飞 | 7000 | 22000 |
| 研发部 | 赵云 | 7000 | 26000 |
| 研发部 | 马超 | 4000 | 27000 |
| 研发部 | 黄忠 | 4000 | 22000 |
| 销售部 | 曹操 | 2000 | 5000 |
| 销售部 | 许褚 | 3000 | 10000 |
| 销售部 | 典韦 | 5000 | 16000 |
| 销售部 | 张辽 | 6000 | 25000 |
| 销售部 | 虚晃 | 9000 | 29000 |
| 销售部 | 曹洪 | 6000 | 26000 |
+-----------+--------+--------+-------+
-- 对部门进行分组 日期进行排序 从当前行加到最后一行求薪水的总和c1
select dname,ename,salary,
sum(salary) over(partition by dname order by hiredate rows between current row and unbounded following) as c1
from employee;
+-----------+--------+--------+-------+
| dname | ename | salary | c1 |
+-----------+--------+--------+-------+
| 研发部 | 刘备 | 3000 | 30000 |
| 研发部 | 关羽 | 5000 | 27000 |
| 研发部 | 张飞 | 7000 | 22000 |
| 研发部 | 赵云 | 7000 | 15000 |
| 研发部 | 马超 | 4000 | 8000 |
| 研发部 | 黄忠 | 4000 | 4000 |
| 销售部 | 曹操 | 2000 | 31000 |
| 销售部 | 许褚 | 3000 | 29000 |
| 销售部 | 典韦 | 5000 | 26000 |
| 销售部 | 张辽 | 6000 | 21000 |
| 销售部 | 虚晃 | 9000 | 15000 |
| 销售部 | 曹洪 | 6000 | 6000 |
+-----------+--------+--------+-------+
分布函数
- cume_dist():在排序或分组后计算占比率的函数
- percent_rank(): (rank - 1) / (rows - 1) 、rank为RANK()函数产生的序号,rows为当前窗口的记录总行数
-- cume_dist()
-- c1是针对所有部门的薪资进行排序后 计算出成员的薪资占比率
-- c2是对部门进行分组 对薪资进行排序 计算成员在当前部门的薪资占比率
select *,
cume_dist() over (order by salary) c1,
cume_dist() over (partition by dname order by salary) c2
from employee;
+-----------+--------+--------+---------------------+---------------------+
| dname | ename | salary | c1 | c2 |
+-----------+--------+--------+---------------------+---------------------+
| 研发部 | 刘备 | 3000 | 0.25 | 0.16666666666666666 | -- c1: 有12个人 比3000少或者等于3000的人就3个 3/12=0.25
| 研发部 | 马超 | 4000 | 0.4166666666666667 | 0.5 | -- c2: 已经排序了 部门有6个成员 比3000少就一个 1/6=0.166...
| 研发部 | 黄忠 | 4000 | 0.4166666666666667 | 0.5 |
| 研发部 | 关羽 | 5000 | 0.5833333333333334 | 0.6666666666666666 |
| 研发部 | 张飞 | 7000 | 0.9166666666666666 | 1 |
| 研发部 | 赵云 | 7000 | 0.9166666666666666 | 1 |
| 销售部 | 曹操 | 2000 | 0.08333333333333333 | 0.16666666666666666 |
| 销售部 | 许褚 | 3000 | 0.25 | 0.3333333333333333 |
| 销售部 | 典韦 | 5000 | 0.5833333333333334 | 0.5 |
| 销售部 | 张辽 | 6000 | 0.75 | 0.8333333333333334 |
| 销售部 | 曹洪 | 6000 | 0.75 | 0.8333333333333334 |
| 销售部 | 虚晃 | 9000 | 1 | 1 |
+-----------+--------+--------+---------------------+---------------------+
-- percent_rank()
-- (rank-1) / (总行数 -1); c1表就是rank
-- 赵云:(1-1)/(6-1)=0
-- 关羽:(3-1)/(6-1)=0.4
select dname,ename,salary,
rank() over(partition by dname order by salary desc) c1,
percent_rank() over(partition by dname order by salary desc) as c2
from employee;
+-----------+--------+--------+-----+-----+
| dname | ename | salary | c1 | c2 |
+-----------+--------+--------+-----+-----+
| 研发部 | 张飞 | 7000 | 1 | 0 |
| 研发部 | 赵云 | 7000 | 1 | 0 |
| 研发部 | 关羽 | 5000 | 3 | 0.4 |
| 研发部 | 马超 | 4000 | 4 | 0.6 |
| 研发部 | 黄忠 | 4000 | 4 | 0.6 |
| 研发部 | 刘备 | 3000 | 6 | 1 |
| 销售部 | 虚晃 | 9000 | 1 | 0 |
| 销售部 | 张辽 | 6000 | 2 | 0.2 |
| 销售部 | 曹洪 | 6000 | 2 | 0.2 |
| 销售部 | 典韦 | 5000 | 4 | 0.6 |
| 销售部 | 许褚 | 3000 | 5 | 0.8 |
| 销售部 | 曹操 | 2000 | 6 | 1 |
+-----------+--------+--------+-----+-----+前后函数
- lead(n) / lag(n)
- 分组中位于当前行后n行(lead)/ 前n行(lag)的记录值。
-- time1列将部门进行分组、时间进行排序 lag(函数)对hiredate进行偏移1 默认为2001-01-01
-- time2 将部门进行分组、时间进行排序 对时间进行偏移1 如果没有要返回的值则用null
select dname,ename,salary,hiredate,
lag(hiredate,1,'2001-01-01') over (partition by dname order by hiredate) as time1,
lag(hiredate,1) over(partition by dname order by hiredate) as time2
from employee;
+-----------+--------+--------+------------+------------+------------+
| dname | ename | salary | hiredate | time1 | time2 |
+-----------+--------+--------+------------+------------+------------+
| 研发部 | 刘备 | 3000 | 2021-11-01 | 2001-01-01 | NULL |
| 研发部 | 关羽 | 5000 | 2021-11-02 | 2021-11-01 | 2021-11-01 |
| 研发部 | 张飞 | 7000 | 2021-11-03 | 2021-11-02 | 2021-11-02 |
| 研发部 | 赵云 | 7000 | 2021-11-04 | 2021-11-03 | 2021-11-03 |
| 研发部 | 马超 | 4000 | 2021-11-05 | 2021-11-04 | 2021-11-04 |
| 研发部 | 黄忠 | 4000 | 2021-11-06 | 2021-11-05 | 2021-11-05 |
| 销售部 | 曹操 | 2000 | 2021-11-01 | 2001-01-01 | NULL |
| 销售部 | 许褚 | 3000 | 2021-11-02 | 2021-11-01 | 2021-11-01 |
| 销售部 | 典韦 | 5000 | 2021-11-03 | 2021-11-02 | 2021-11-02 |
| 销售部 | 张辽 | 6000 | 2021-11-04 | 2021-11-03 | 2021-11-03 |
| 销售部 | 虚晃 | 9000 | 2021-11-05 | 2021-11-04 | 2021-11-04 |
| 销售部 | 曹洪 | 6000 | 2021-11-06 | 2021-11-05 | 2021-11-05 |
+-----------+--------+--------+------------+------------+------------+
select dname,ename,salary,hiredate,
lead(hiredate,1,'2001-01-01') over (partition by dname order by hiredate) as time1,
lead(hiredate,1) over(partition by dname order by hiredate) as time2
from employee;
+-----------+--------+--------+------------+------------+------------+
| dname | ename | salary | hiredate | time1 | time2 |
+-----------+--------+--------+------------+------------+------------+
| 研发部 | 刘备 | 3000 | 2021-11-01 | 2021-11-02 | 2021-11-02 |
| 研发部 | 关羽 | 5000 | 2021-11-02 | 2021-11-03 | 2021-11-03 |
| 研发部 | 张飞 | 7000 | 2021-11-03 | 2021-11-04 | 2021-11-04 |
| 研发部 | 赵云 | 7000 | 2021-11-04 | 2021-11-05 | 2021-11-05 |
| 研发部 | 马超 | 4000 | 2021-11-05 | 2021-11-06 | 2021-11-06 |
| 研发部 | 黄忠 | 4000 | 2021-11-06 | 2001-01-01 | NULL |
| 销售部 | 曹操 | 2000 | 2021-11-01 | 2021-11-02 | 2021-11-02 |
| 销售部 | 许褚 | 3000 | 2021-11-02 | 2021-11-03 | 2021-11-03 |
| 销售部 | 典韦 | 5000 | 2021-11-03 | 2021-11-04 | 2021-11-04 |
| 销售部 | 张辽 | 6000 | 2021-11-04 | 2021-11-05 | 2021-11-05 |
| 销售部 | 虚晃 | 9000 | 2021-11-05 | 2021-11-06 | 2021-11-06 |
| 销售部 | 曹洪 | 6000 | 2021-11-06 | 2001-01-01 | NULL |
+-----------+--------+--------+------------+------------+------------+头尾函数
- FIRST_VALUE、LAST_VALUE
- 查询结果中返回对应列的第一个值和最后一个值。
-- 按照日期进行排序 查询第一个入职和最后一个入职员工的薪资
select dname,ename,salary,hiredate,
first_value(salary) over (partition by dname order by hiredate) as first,
last_value(salary) over(partition by dname order by hiredate) as last -- last 就表示当前salary
from employee;
+-----------+--------+--------+------------+-------+------+
| dname | ename | salary | hiredate | first | last |
+-----------+--------+--------+------------+-------+------+
| 研发部 | 刘备 | 3000 | 2021-11-01 | 3000 | 3000 |
| 研发部 | 关羽 | 5000 | 2021-11-02 | 3000 | 5000 |
| 研发部 | 张飞 | 7000 | 2021-11-03 | 3000 | 7000 |
| 研发部 | 赵云 | 7000 | 2021-11-04 | 3000 | 7000 |
| 研发部 | 马超 | 4000 | 2021-11-05 | 3000 | 4000 |
| 研发部 | 黄忠 | 4000 | 2021-11-06 | 3000 | 4000 |
| 销售部 | 曹操 | 2000 | 2021-11-01 | 2000 | 2000 |
| 销售部 | 许褚 | 3000 | 2021-11-02 | 2000 | 3000 |
| 销售部 | 典韦 | 5000 | 2021-11-03 | 2000 | 5000 |
| 销售部 | 张辽 | 6000 | 2021-11-04 | 2000 | 6000 |
| 销售部 | 虚晃 | 9000 | 2021-11-05 | 2000 | 9000 |
| 销售部 | 曹洪 | 6000 | 2021-11-06 | 2000 | 6000 |
+-----------+--------+--------+------------+-------+------+其他函数
- nth_value 返回指定列在指定排序顺序下的第n个值。其中n由用户指定,可以是任何正整数。如果指定的行数超过实际行数,则返回NULL。
- ntile 将结果集分成指定数量的相等大小的桶或组的SQL函数
-- 查询每个部门截止目前薪资排在第二或者第三的信息
-- 对部门进行分组 对eid进行排序 排序后查看薪资是第二的然后展示出来two列
select *, nth_value(salary,2) over(partition by dname order by eid) two,
nth_value(salary,3) over(partition by dname order by eid) three
from employee;
+-----------+------+--------+------------+--------+------+-------+
| dname | eid | ename | hiredate | salary | two | three |
+-----------+------+--------+------------+--------+------+-------+
| 研发部 | 1001 | 刘备 | 2021-11-01 | 3000 | NULL | NULL |
| 研发部 | 1002 | 关羽 | 2021-11-02 | 5000 | 5000 | NULL |
| 研发部 | 1003 | 张飞 | 2021-11-03 | 7000 | 5000 | 7000 |
| 研发部 | 1004 | 赵云 | 2021-11-04 | 7000 | 5000 | 7000 |
| 研发部 | 1005 | 马超 | 2021-11-05 | 4000 | 5000 | 7000 |
| 研发部 | 1006 | 黄忠 | 2021-11-06 | 4000 | 5000 | 7000 |
| 销售部 | 1007 | 曹操 | 2021-11-01 | 2000 | NULL | NULL |
| 销售部 | 1008 | 许褚 | 2021-11-02 | 3000 | 3000 | NULL |
| 销售部 | 1009 | 典韦 | 2021-11-03 | 5000 | 3000 | 5000 |
| 销售部 | 1010 | 张辽 | 2021-11-04 | 6000 | 3000 | 5000 |
| 销售部 | 1011 | 虚晃 | 2021-11-05 | 9000 | 3000 | 5000 |
| 销售部 | 1012 | 曹洪 | 2021-11-06 | 6000 | 3000 | 5000 |
+-----------+------+--------+------------+--------+------+-------+
-- 将每个部门员工按照编号分成3组
select *, ntile(3) over(partition by dname order by eid) nt
from employee;
+-----------+------+--------+------------+--------+----+
| dname | eid | ename | hiredate | salary | nt |
+-----------+------+--------+------------+--------+----+
| 研发部 | 1001 | 刘备 | 2021-11-01 | 3000 | 1 |
| 研发部 | 1002 | 关羽 | 2021-11-02 | 5000 | 1 |
| 研发部 | 1003 | 张飞 | 2021-11-03 | 7000 | 2 |
| 研发部 | 1004 | 赵云 | 2021-11-04 | 7000 | 2 |
| 研发部 | 1005 | 马超 | 2021-11-05 | 4000 | 3 |
| 研发部 | 1006 | 黄忠 | 2021-11-06 | 4000 | 3 |
| 销售部 | 1007 | 曹操 | 2021-11-01 | 2000 | 1 |
| 销售部 | 1008 | 许褚 | 2021-11-02 | 3000 | 1 |
| 销售部 | 1009 | 典韦 | 2021-11-03 | 5000 | 2 |
| 销售部 | 1010 | 张辽 | 2021-11-04 | 6000 | 2 |
| 销售部 | 1011 | 虚晃 | 2021-11-05 | 9000 | 3 |
| 销售部 | 1012 | 曹洪 | 2021-11-06 | 6000 | 3 |
+-----------+------+--------+------------+--------+----+
-- 取出每个部门的第一组员工
select * from
(select *,ntile(3) over(partition by dname order by eid) as nt from employee) a
where a.nt = 1;
| dname | eid | ename | hiredate | salary | nt |
+-----------+------+--------+------------+--------+----+
| 研发部 | 1001 | 刘备 | 2021-11-01 | 3000 | 1 |
| 研发部 | 1002 | 关羽 | 2021-11-02 | 5000 | 1 |
| 销售部 | 1007 | 曹操 | 2021-11-01 | 2000 | 1 |
| 销售部 | 1008 | 许褚 | 2021-11-02 | 3000 | 1 |
+-----------+------+--------+------------+--------+----+窗口函数总结
视图(View)
- 在数据库中,视图(View)是一个虚拟的表格,其内容由查询语句定义。
创建视图
| 属性 | 说明 |
|---|---|
| create view 视图名 as 查询语句 | 创建视图 |
use mydb2;
-- 查看表内容
select * from employee;
+-----------+------+--------+------------+--------+
| dname | eid | ename | hiredate | salary |
+-----------+------+--------+------------+--------+
| 研发部 | 1001 | 刘备 | 2021-11-01 | 3000 |
| 研发部 | 1002 | 关羽 | 2021-11-02 | 5000 |
| 研发部 | 1003 | 张飞 | 2021-11-03 | 7000 |
| 研发部 | 1004 | 赵云 | 2021-11-04 | 7000 |
| 研发部 | 1005 | 马超 | 2021-11-05 | 4000 |
| 研发部 | 1006 | 黄忠 | 2021-11-06 | 4000 |
| 销售部 | 1007 | 曹操 | 2021-11-01 | 2000 |
| 销售部 | 1008 | 许褚 | 2021-11-02 | 3000 |
| 销售部 | 1009 | 典韦 | 2021-11-03 | 5000 |
| 销售部 | 1010 | 张辽 | 2021-11-04 | 6000 |
| 销售部 | 1011 | 虚晃 | 2021-11-05 | 9000 |
| 销售部 | 1012 | 曹洪 | 2021-11-06 | 6000 |
+-----------+------+--------+------------+--------+
-- 子查询 查询薪资大于3000所有的员工
select * from employee where salary > all(select salary from employee where salary = 3000);
+-----------+------+--------+------------+--------+
| dname | eid | ename | hiredate | salary |
+-----------+------+--------+------------+--------+
| 研发部 | 1002 | 关羽 | 2021-11-02 | 5000 |
| 研发部 | 1003 | 张飞 | 2021-11-03 | 7000 |
| 研发部 | 1004 | 赵云 | 2021-11-04 | 7000 |
| 研发部 | 1005 | 马超 | 2021-11-05 | 4000 |
| 研发部 | 1006 | 黄忠 | 2021-11-06 | 4000 |
| 销售部 | 1009 | 典韦 | 2021-11-03 | 5000 |
| 销售部 | 1010 | 张辽 | 2021-11-04 | 6000 |
| 销售部 | 1011 | 虚晃 | 2021-11-05 | 9000 |
| 销售部 | 1012 | 曹洪 | 2021-11-06 | 6000 |
+-----------+------+--------+------------+--------+
-- 查询薪资等于3000的
select salary from employee where salary = 3000;
+--------+
| salary |
+--------+
| 3000 |
| 3000 |
+--------+
-- 创建视图 想等于给一个查询语句的表起了一个单独的名字 相当于映射到一个表中了 而这个表则是虚拟的
create view view1 as select salary from employee where salary = 3000;
select * from view1;
+--------+
| salary |
+--------+
| 3000 |
| 3000 |
+--------+修改视图
| 属性 | 说明 |
|---|---|
| alter view 原视图名 as 查询语句 | 修改视图 |
-- 修改视图
alter view view1 as select * from employee where eid = 1012;
select * from view1;
+-----------+------+--------+------------+--------+
| dname | eid | ename | hiredate | salary |
+-----------+------+--------+------------+--------+
| 销售部 | 1012 | 曹洪 | 2021-11-06 | 6000 |
+-----------+------+--------+------------+--------+更新视图
- 包含聚合函数(如SUM、COUNT等)或DISTINCT关键字的视图;
- 使用了GROUP BY子句的视图;
- 基于多张表的视图中,包含有联结(JOIN)操作且ON子句中含有条件表达式的视图;
- 视图定义中包含union、union all、cross join等运算符的视图。
这些视图不可以更新是因为它们涉及到底层表的多行数据,而更新操作只能操作单个行。此外,一些聚合函数不能被反向计算,因此也不能进行更新。
| 属性 | 说明 |
|---|---|
| update 视图名 set 更新的列名=值 | 更新视图 |
| rename table 视图名 to 新视图名 | 重命名视图 |
| drop view 视图名 | 删除视图 |